
The final component of an Internest transaction that we are going to look at is the Service. There are many definitions of what a service is, but for the purpose of this article, a service is a set of standards that software platforms can use to talk to other software platforms to get and transfer information without a human component. Below is a diagram of a general set of these standards that are used: a Security component, a Reliable Messaging component, the Transaction, the actual Message and it's language (XML in this case), and the Metadata to put it all together.

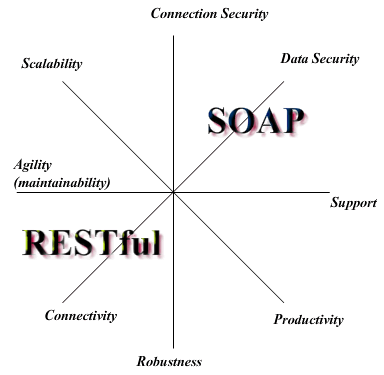
There are couple commonly used technologies when discussing Services: SOAP, XML, and WSDL. SOAP and WSDL are both protocols that utilize the XML language. Soap is "a lightweight protocol for the exchange of information in a decentralized, distributed environment" and acts as a virtual envelope to send data. WSDL is then used as the diction and syntax to the message that allows completely different applications to communicate with each other, very similar to the Universal Translator in Star Trek.

The idea of a Service has been around a while, they just have not always been publicly available or documented. Microsoft is infamous for it's products interoperability, and the words "web service" were first documented as being uttered by Bill Gates at a developer's conference. EDI was the first to try to develop some type of data interaction. However, it ended up being costly and hard to implement. Then once the Web starting gaining ground, SOAP was developed, and that opened the door to the Web service we know today.

Additional Resources:
http://en.wikipedia.org/wiki/Web_service
http://www.w3schools.com/webservices/default.asp
http://www.webopedia.com/TERM/W/Web_Services.html
http://www.businessweek.com/technology/content/feb2005/tc2005028_8000_tc203.htm
http://ws.apache.org/
http://www.ibm.com/developerworks/webservices/
http://msdn.microsoft.com/en-us/library/ms950421.aspx
http://www.innoq.com/resources/ws-standards-poster/
http://www.informationweek.com/news/6506480

















{kind=link}
{kind=link}